Dynamic predictions for assessing hard-to-place deceased donor kidneys
Grace Guan1, Joachim Studnia1, Sanjit Neelam1, Xingxing S Cheng2, Marc L Melcher3, Nikhil Agarwal4, Paulo Somaini5, Itai Ashlagi1.
1Management Science and Engineering, Stanford University, Stanford, CA, United States; 2Nephrology, Stanford University, Stanford, CA, United States; 3Surgery, Stanford University, Stanford, CA, United States; 4Economics, Massachusetts Institute of Technology, Cambridge, MA, United States; 5Graduate School of Business, Stanford University, Stanford, CA, United States
Introduction: Since 2022, out-of-sequence placements for deceased donor kidneys have become significantly more prevalent, and these placements are invoked in an ad-hoc manner by organ procurement organizations. Considering ongoing efforts to transition all solid organ allocation in the U.S. to a continuous distribution system, which will only magnify the increasing complexity of center-OPO relations, the rise of discretionary offering is especially problematic. The Organ Procurement and Transplantation Network (OPTN) is currently searching for a more structured approach for accelerated placement of hard-to-place deceased donor kidneys. The purpose of this study is to develop machine learning (ML) models to predict the risk of nonuse using information available at distinct time points throughout the allocation process, and to utilize these ML predictions to evaluate the characteristics of kidneys currently placed out-of-sequence.
Methods: Using OPTN data from January 1, 2022 to December 31, 2023, we trained 5 ML models to predict nonuse using information available at distinct time points: (1) pre-offer; (2) clamp time, without refusal information; (3) clamp time, with refusal information; (4) 3 hours post-clamp, without refusal information; and (5) 3 hours post-clamp, with refusal information. We assumed that biopsy results would be available 3 hours after the clamp. Refusal information included the number of unique centers that sent simultaneous refusals before the model’s prediction time. We used the ML-predicted probabilities as a proxy for the difficulty of placing a kidney.
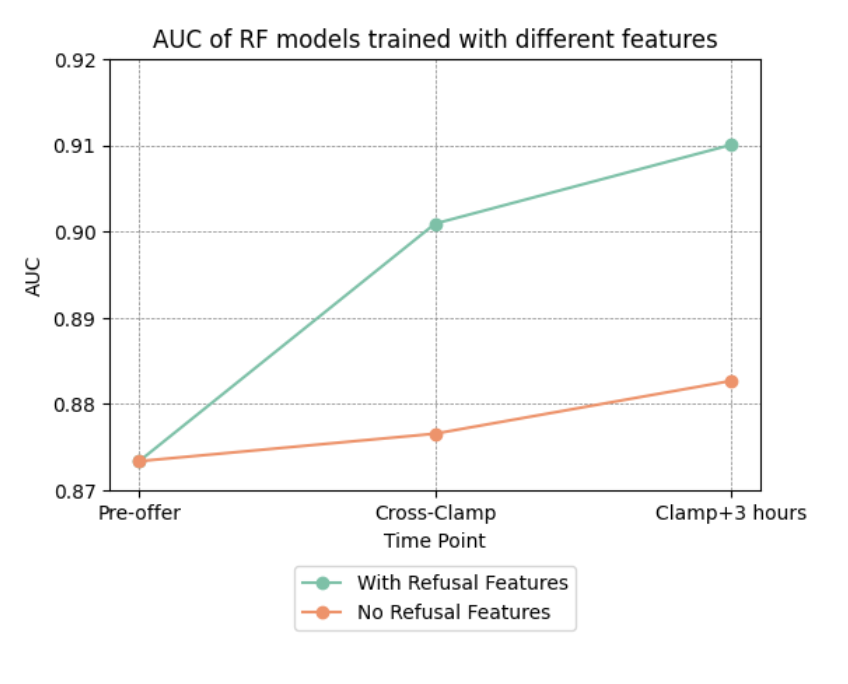
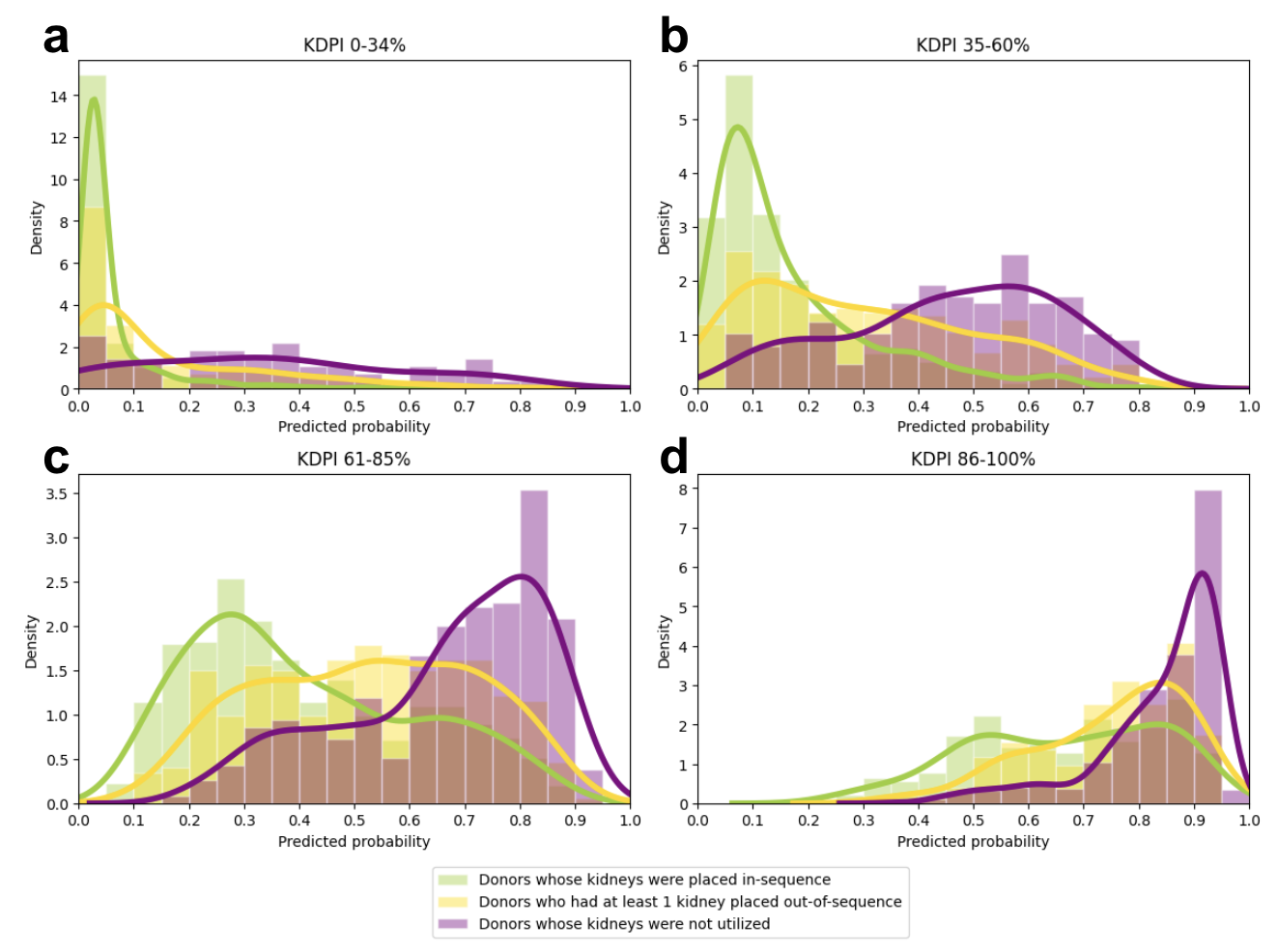
Results: Adding refusal information up to clamp time improves model accuracy by 4% (83% vs. 79%) and outperforms a model that uses biopsy but no refusal information (accuracy 81%). Similar results are achieved for the area-under-the-curve (AUC) metric (Figure 1). The number of unique centers that have sent simultaneous refusals for >5 patients is the second most important predictor of nonuse at clamp time and the most important predictor three hours after clamp. The ML model can identify which kidneys are hard-to-place better than the Kidney Donor Profile Index (KDPI), as there is separation of probabilities by donor outcomes even within KDPI buckets (Figure 2). The predicted probabilities for nonuse are higher for kidneys placed out-of-sequence and unused kidneys compared to kidneys placed in-sequence (Figure 2).
Conclusions: The ML predictions are better able to identify hard-to-place kidneys compared to the Kidney Donor Profile Index. Moreover, refusal information improves identification of hard-to-place kidneys. Identifying such kidneys early in the allocation process (e.g., cross-clamp) based on objective and easily obtainable real-time information has the potential to improve the efficiency of accelerated placement and to achieve better outcomes for all patients.
[1] Organ Procurement and Transplantation Network
[2] Deceased Donor Kidney
[3] Organ allocation
[4] Organ utilization
[5] Machine learning
[6] Artificial Intelligence
[7] Big Data